Traditional Business Rules vs. Predictive Software Features
I spent nearly half of my career writing requirements and developing and testing software the traditional way....


|
CONSTRUCTION & REAL ESTATE
|
 |
|
Discover how crafting a robust AI data strategy identifies high-value opportunities. Learn how Ryan Companies used AI to enhance efficiency and innovation.
|
| Read the Case Study ⇢ |
|
LEGAL SERVICES
|
 |
|
Discover how a global law firm uses intelligent automation to enhance client services. Learn how AI improves efficiency, document processing, and client satisfaction.
|
| Read the Case Study ⇢ |
|
HEALTHCARE
|
 |
|
A startup in digital health trained a risk model to open up a robust, precise, and scalable processing pipeline so providers could move faster, and patients could move with confidence after spinal surgery.
|
| Read the Case Study ⇢ |
|
LEGAL SERVICES
|
 |
|
Learn how Synaptiq helped a law firm cut down on administrative hours during a document migration project.
|
| Read the Case Study ⇢ |
|
GOVERNMENT/LEGAL SERVICES
|
 |
|
Learn how Synaptiq helped a government law firm build an AI product to streamline client experiences.
|
| Read the Case Study ⇢ |
 |
|
Mushrooms, Goats, and Machine Learning: What do they all have in common? You may never know unless you get started exploring the fundamentals of Machine Learning with Dr. Tim Oates, Synaptiq's Chief Data Scientist. You can read and visualize his new book in Python, tinker with inputs, and practice machine learning techniques for free. |
| Start Chapter 1 Now ⇢ |



Sentiment analysis is a useful tool for organizations aiming to understand customer preferences, gauge public opinion, and monitor brand reputation. We covered a basic approach — naive, lexicon-based sentiment analysis — in a previous blog post. Now, we’ll model a more effective approach: n-gram lexicon-based sentiment analysis.
Let's briefly revisit the concept of sentiment analysis. It’s a natural language processing (NLP) technique used to categorize the sentiment expressed in a piece of text. NLP itself is a sub-discipline of AI concerned with enabling computers to interpret natural language, which is a language that has evolved for interpersonal communication, such as English or ASL. So, sentiment analysis can be understood as a specific application of AI that is concerned with interpreting the type of emotional sentiment expressed by a piece of text written in human language.
Naive, lexicon-based sentiment analysis breaks a piece of text into individual tokens, typically words, and then looks up the tokens in a lexicon to retrieve their numeric sentiment scores — positive, negative, or neutral (zero). These scores are summed or averaged to compute an overall sentiment score for the text. For an in-depth explanation and example of naive, lexicon-based sentiment analysis in action, read our blog post about it.
N-gram, lexicon-based sentiment analysis breaks a piece of text into tokens, then combines those tokens into n-grams, which are sequences of n consecutive tokens. In this context, n can be any whole number, allowing for the analysis of pairs (bigrams), triplets (trigrams), or longer sequences of tokens as single entities. This approach recognizes that an n-gram may convey a different sentiment than the sum of its parts. Consider a bigram like “not bad,” which has a positive sentiment, despite the tokens “not” and “bad” suggesting a negative sentiment.

Let’s compare the performance of the naive approach and the n-gram approach to lexicon-based sentiment analysis in a practical scenario. We have a web-scraped dataset containing approximately sixteen thousand customer reviews for a Sephora lip mask product. We want to know how customers feel about the product.
The N-gram Approach
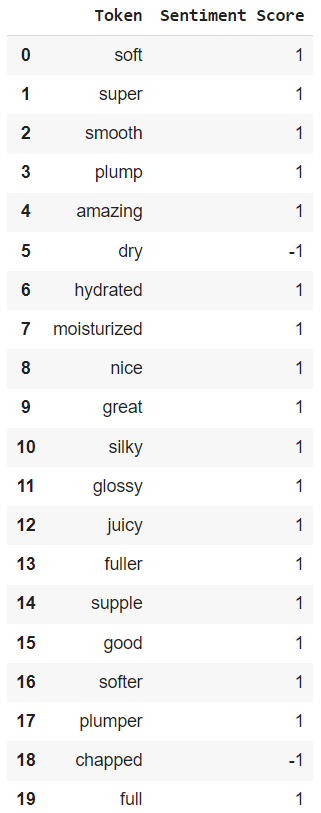
We focus on the n-gram “makes my lips feel [blank].” This five-gram captures a specific and common way customers might express their satisfaction or dissatisfaction with the product's primary function — treating the lips. We find every instance of this n-gram in our dataset and identify the 20 most common tokens that customers use to fill in the [blank]. Next, we manually assign either a positive or a negative sentiment score to each of the identified tokens. The result is a lexicon we can use for n-gram, lexicon-based sentiment analysis, pictured below.
The Naive Approach
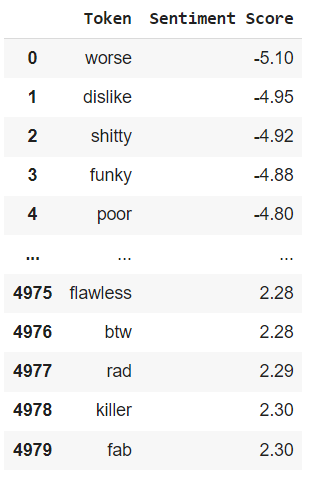
We need a much larger lexicon to conduct naive, lexicon-based sentiment analysis. Fortunately, we don’t have to create one ourselves. We borrow a beauty domain-specific lexicon created by the Stanford Natural Language Processing Group. It contains about five thousand tokens tagged with sentiment scores, pictured in excerpt below.
Results & Comparison
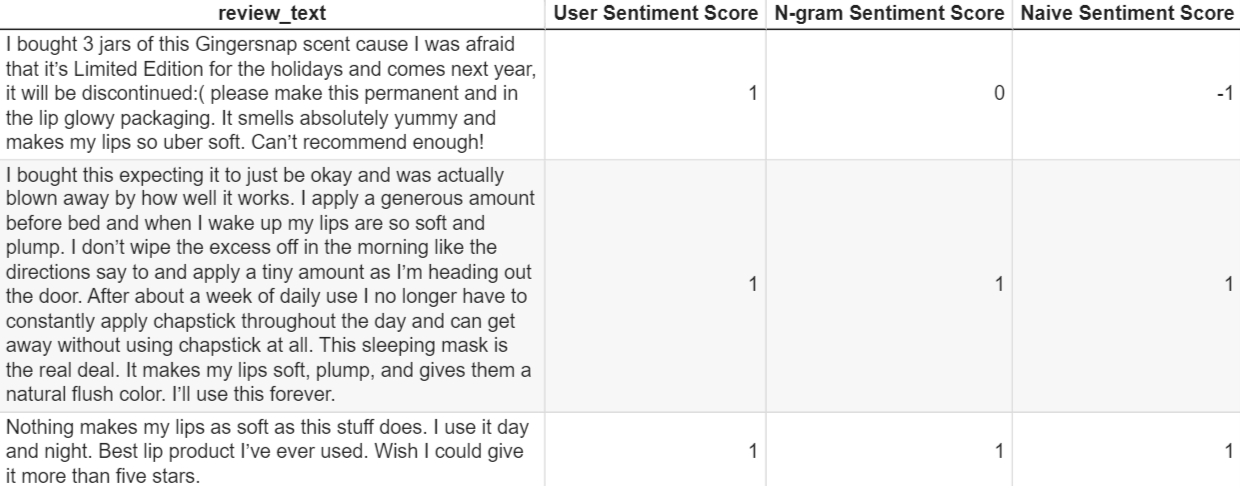
We pull a random sample of three reviews containing the n-gram “makes lips feel [blank]” from our dataset and manually assign each review a "User Sentiment Score." We also compute an "N-gram Sentiment Score" using our n-gram lexicon and a "Naive Sentiment Score" using on our naive lexicon. We return the results pictured below.
All three reviews exhibit a positive sentiment, as indicated by their User Sentiment Score. Both of our approaches to lexicon-based sentiment analysis correctly identified two of the three reviews as expressing positivity. However, the n-gram approach miscategorized the first review because the token "so" following the five-gram "makes my lips feel [blank]" does not appear in our n-gram lexicon. Conversely, the naive approach miscategorized the first review as negative because the sentiment scores of its individual tokens averaged out to a negative value.
These mistakes illustrate the relative strengths and weaknesses of our two approaches. N-gram, lexicon-based sentiment analysis excels at categorizing reviews that contain a specified n-gram followed by a recognized token, but it is limited by the scope of its lexicon. Naive, lexicon-based sentiment analysis can categorize any review because it is not reliant on the presence of a specified n-gram, but it cannot take sequence or context into account — it analyzes a review as the sum of its individual parts, which may convey a different sentiment than the whole.
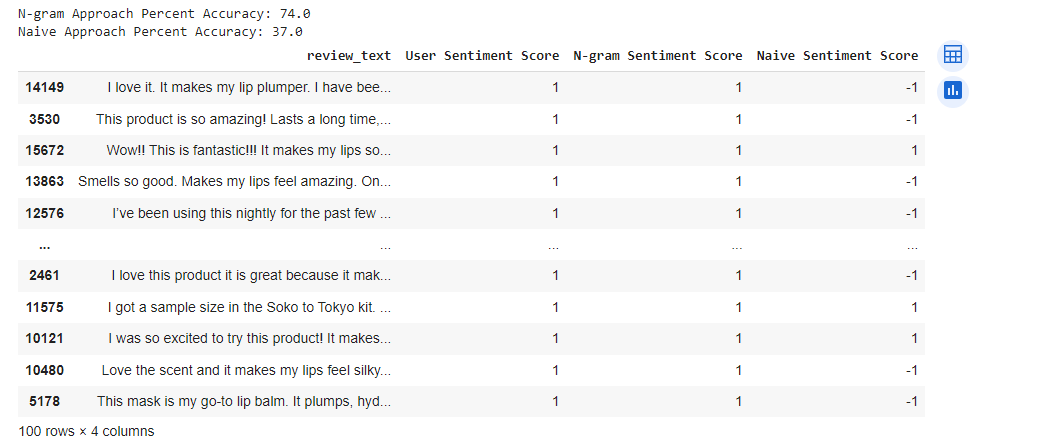
Which approach is better overall for our dataset? We pull a random sample of 100 reviews containing the n-gram “makes lips feel [blank]” from our dataset" and repeat the scoring process. We return the results pictured below.
The N-gram Sentiment Score matched the User Sentiment Score — the correct sentiment score — for 74 percent of the reviews we sampled, whereas the Naive Sentient Score matched the User Sentiment Score for only 34 percent of the reviews we sampled. These results indicate that the n-gram approach is better suited to our dataset.
The two approaches we’ve explored each have their own advantages. On the one hand, naive, lexicon-based sentiment analysis offers a straightforward way to gauge the sentiment conveyed by a text based on the individual tokens that appear within it. This approach is useful in scenarios where the order or context in which tokens appear has little impact on the sentiment expressed. On the other hand, n-gram, lexicon-based sentiment analysis shines in scenarios where sentiment is strongly informed by the order or context in which tokens appear.

Photo by Erin Minuskin on Unsplash
Synaptiq is an AI and data science consultancy based in Portland, Oregon. We collaborate with our clients to develop human-centered products and solutions. We uphold a strong commitment to ethics and innovation.
Contact us if you have a problem to solve, a process to refine, or a question to ask.
You can learn more about our story through our past projects, our blog, or our podcast.