Sentiment analysis is a must-have for organizations with a business-to-consumer (B2C) business model. This natural language processing technique can be used to discern the sentiment of customer reviews, revealing valuable insights that would otherwise be lost in a sea of unstructured data. Such insights are key for B2C organizations striving to understand customer stories and remain attuned to consumer needs.
Tokenization is a fundamental step in sentiment analysis. It is the process of splitting a single piece of text into multiple smaller units (tokens) for processing. Let’s explore how B2C organizations can use tokenization with a practical business case: performing sentiment analysis on customer reviews.
Note: "Tokenization" can also refer to a process in which sensitive data is substituted with a unique non-sensitive equivalent, called a token. We’ll cover that kind of tokenization in a future blog post. ;)

Sourcing a Suitable Dataset
Our first step is to gather data suitable for tokenization. We’ve procured an open-source dataset from the online data science community Kaggle that contains about one million customer reviews of Sephora skincare products collected via web scraping. We’ve narrowed down our dataset by filtering for customer reviews specifically related to the product "Lip Sleeping Mask Intense Hydration with Vitamin C," resulting in a subset of 199 customer reviews.
Tokenizing the Customer Reviews
Our next step is to tokenize the data we’ve gathered. Tokenization entails dividing a single piece of text (in our case, a customer review) into smaller pieces, or "tokens." Tokens can range in size from whole words to granular units like subword pieces, which are generated by progressively complicated methods such as Byte-Pair Encoding.
For the sake of simplicity, let’s settle on word-level tokenization. We've used the Natural Language Toolkit or "NLTK" — a popular Python package for natural language processing for English — to split each of our 199 customer reviews into a series of words and punctuation marks. A single review that reads, "This lip mask is awesome!" thus becomes six tokens (five words and an exclamation point): "This" "lip" "mask" "is" "awesome" "!"
The histogram below displays the 10 most frequently occurring tokens within our dataset. On the x-axis, we have the tokens themselves, and on the y-axis, we have the total number of times each token appears across our collection of 199 customer reviews. We can see that two of these 10 tokens are punctuation marks, and a further seven are what we call "stopwords." Stopwords are common words with very little semantic meaning, such as articles, prepositions, and conjunctions. They are generally not useful in the context of sentiment analysis.
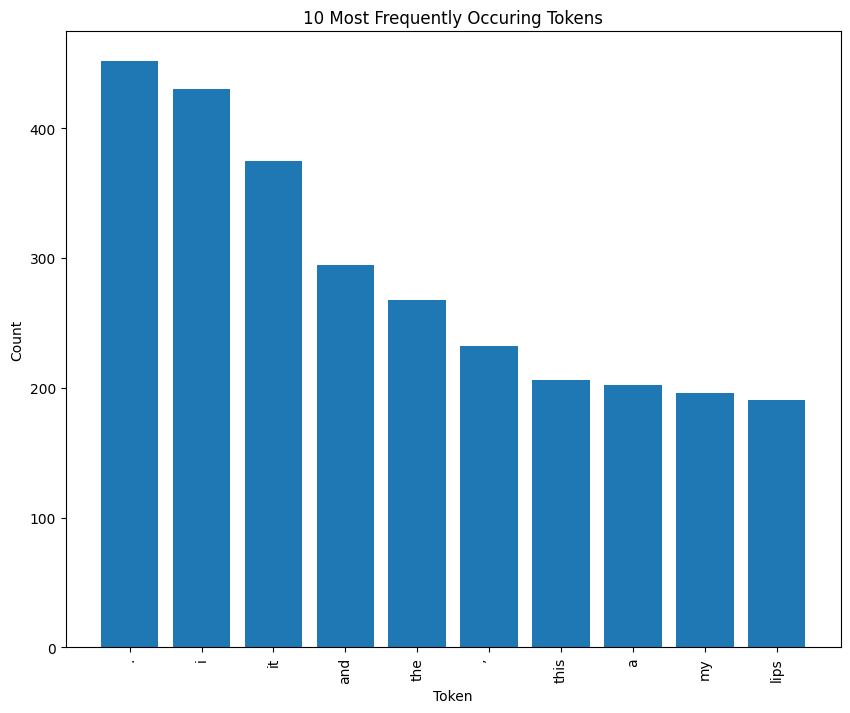
Note: Reviews were converted to lowercase prior to tokenization.
Removing the punctuation marks and stopwords from our dataset yields a much more interesting histogram (below). It’s no surprise to find the tokens "lips," "lip," and "product" on the x-axis — remember, we’ve tokenized reviews for a lip mask skincare product— but the other eight tokens hint at customer sentiment. For example, the token "dry" could convey a positive sentiment (e.g., "my lips were dry, but this product helped") or a negative sentiment (e.g., "this product made my lips feel dry"), depending on the context in which it appears.
We’ve used tokenization to turn our customer reviews into bite-sized tokens. Our final step is to perform sentiment analysis to evaluate these tokens in context (where they’re useful) and interpret the results.
Performing Sentiment Analysis
Sentiment analysis is a natural language processing technique used to categorize the sentiment expressed in a piece of text as positive, negative, or neutral. We've employed lexicon-based sentiment analysis to cagegorize a single customer review from our dataset: "It is so moisturizing and keeps my lips super soft and hydrated. This approach involves matching each token in the review with a predefined lexicon to get its sentiment score — a process similar to “looking up” a word in the dictionary to get its definition. We’ve used a domain-specific lexicon tailored to the makeup and beauty market created by the Stanford Natural Language Processing Group.
The figure below shows the sentiment scores assigned to each token in the customer review. We can speculate that the tokens "moisturizing," “super,” “soft,” and “hydrated” have a positive sentiment score because they often express desirable qualities in the context of the beauty market, whereas the tokens "keeps" and "lips" have a negative sentiment score because they often express undesirable qualities (e.g., "keeps drying out my lips).
This example shows how B2C organizations can use sentiment analysis to extract insights from customer reviews. Businesses can understand customer sentiments, identify areas of improvement, and enhance their products or services to better meet consumer needs by tokenizing and analyzing customer feedback in aggregate.
Photo by Oleg Moroz on Unsplash
About Synaptiq
Synaptiq is an AI and data science consultancy based in Portland, Oregon. We collaborate with our clients to develop human-centered products and solutions. We uphold a strong commitment to ethics and innovation.
Contact us if you have a problem to solve, a process to refine, or a question to ask.
You can learn more about our story through our past projects, our blog, or our podcast.