

AI in Financial Services
AI in financial services isn’t new. Banks, insurers, and capital markets firms have been using machine learning for...


|
AI & DATA STRATEGY
|
 |
|
Synaptiq helps you develop your AI and data strategy as well as accelerate your roadmap to achieve successful business outcomes. Assess your AI and data readiness so you can prioritize the gaps you need to fill.
|
| Read More ⇢ |
|
DATALAKE
|
 |
|
Synaptiq helps you unify structured and unstructured data into a secure, compliant data lake that powers AI, advanced analytics and real-time decision-making across your business.
|
| Read More ⇢ |
|
AI AGENTS & CHATBOTS
|
 |
|
Synaptiq helps you create AI agents and chatbots that leverage your proprietary data to automate tasks, improve efficiency, and deliver reliable answers within your workflows.
|
| Read More ⇢ |
|
LEGAL SERVICES
|
 |
|
Learn how Synaptiq helped a law firm cut down on administrative hours during a document migration project.
|
| Read the Case Study ⇢ |
|
GOVERNMENT/LEGAL SERVICES
|
 |
|
Learn how Synaptiq helped a government law firm build an AI product to streamline client experiences.
|
| Read the Case Study ⇢ |
 |
|
Mushrooms, Goats, and Machine Learning: What do they all have in common? You may never know unless you get started exploring the fundamentals of Machine Learning with Dr. Tim Oates, Synaptiq's Chief Data Scientist. You can read and visualize his new book in Python, tinker with inputs, and practice machine learning techniques for free. |
| Start Chapter 1 Now ⇢ |



At most companies, employees need a quick and easy way to search through a disorganized repository of documents to answer a pressing question or to provide to a customer. Sounds easy, right? Actually, it’s a big challenge for many companies unless they invest in a pricey asset or content management system that organizes content in a way that is easily searchable. So, what’s the alternative?
Just Google it! The solution to this problem is a search engine that retrieves items based on their fit with user-inputted criteria, also known as user queries. But who has their own proprietary Google search for your documents and content, right? We at Synaptiq have helped clients solve these problems and here is an overview of our approach.
To build a search engine, we first need to decide how it will measure alignment between user queries and available content or documents. One common method is keyword search, where the engine counts how often words from the query appear in each document, with higher counts indicating greater relevancy. However, keyword-search engines struggle in situations where some query words carry more significance than others. For instance, a keyword-search engine given the query “SALES REPORT 2024” would consider the text “SALES SALES SALES” and “SALES REPORT-2024” as similar, since both have a query word count of three.
Semantic search is another common method of measuring relevancy, where the engine transforms the query and the documents into vectors (lists of numbers) and then calculates the distance between the vectors, with less distance indicating greater alignment. Semantic search engines typically work as follows:
Step 1: Tokenize the query and document text
Tokenization is the process of breaking down text into smaller units for analysis. We go into greater detail in another blog post here: Customer Review Sentiment Analysis: A Business Case for Tokenization.
Step 2: Transform the tokenized text into vectors
This is a process called embedding. After tokenized text is transformed into vectors called embeddings using a machine-learning model, these represent text (words, sentences, paragraphs) in a high-dimensional space—similar to Cartesian coordinates but with hundreds or even thousands of dimensions (commonly 768 or 1536). Each dimension captures a specific feature of the text. In this high-dimensional space, proximity between vectors indicates semantic similarity. For instance, the embeddings of "cat" and "feline" would be close, while "cat" and "car" would be farther apart.
Step 3: Calculate the relevancy of content to the query
By calculating the distances between the query and content/document embeddings using measures like cosine similarity or Euclidean distance, we can identify the content or documents that are the closest, or most relevant, to the user’s query. This technique enables the retrieval of results that align with the query's meaning, not just the query’s words.
To compare keyword and semantic search, we can test both methods on a tabular dataset from Kaggle. For example, let’s say we want to answer the following question using keyword search first: “what is machine learning.” Using the Kaggle dataset of 337 rows, each row represents a Medium article on AI, machine learning, or data science. While it also has several columns, we only care about two: `title` and `body`, which contain the article’s title and body text, respectively. Below is a preview of the first three rows of `title` and `body`.
Then, we define and apply a function that counts how often the query words appear in the title or body of each article and returns the titles of the three articles with the highest count of query words.
The results above are not particularly relevant to our query. While these articles frequently mention the words in the query, they do not address the underlying question: “What is machine learning?”
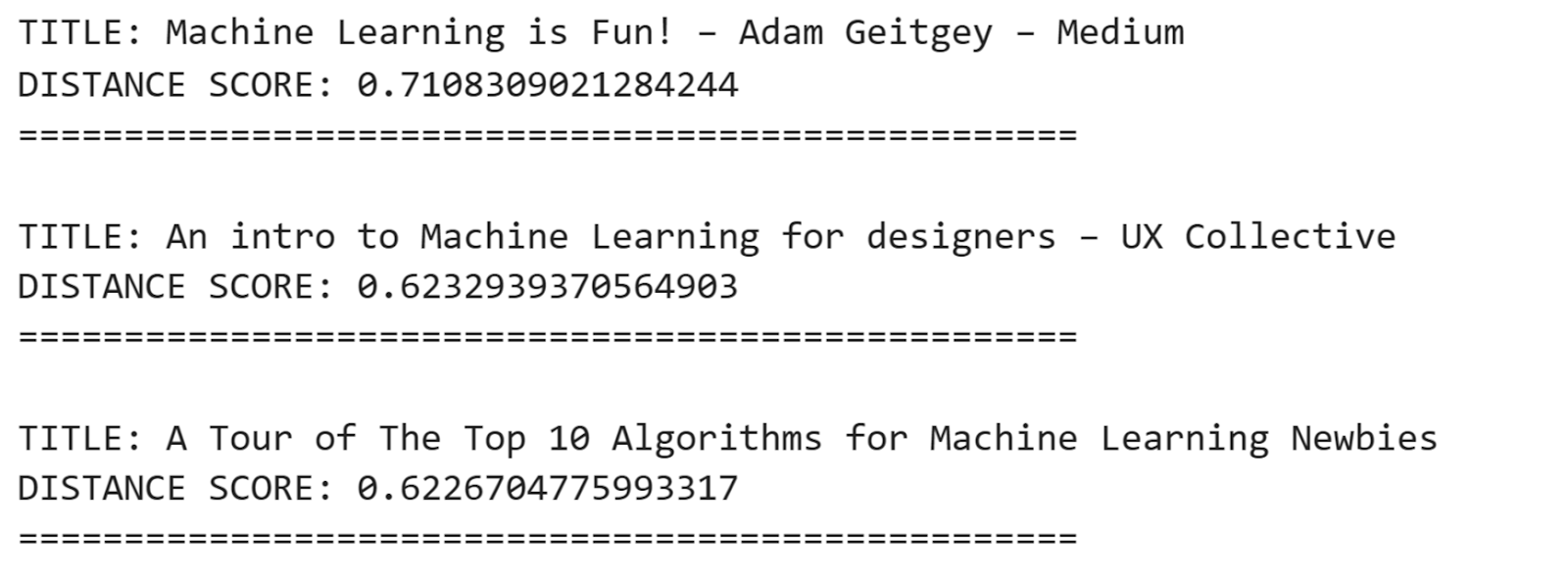
The keyword search didn’t retrieve documents relevant to our query, so let’s see if semantic search performs better. We use a pre-trained machine learning model to generate sentence embeddings for each article in our dataset and our user query: “what is machine learning.” We then apply a function that calculates the distance between the query embedding and each article embedding, returning the titles of the three articles whose embeddings are closest to the query embedding.
The results are much more relevant than the keyword search results. For example, let’s look at the body of the first result. The first sentence introduces the article as “The world’s easiest introduction to Machine Learning,” so it answers the query, “what is machine learning.” The second result is also an introduction to machine learning, while the third explains common machine learning algorithms—not a perfect match, but still more relevant than the keyword search results.
This comparison demonstrates that semantic search using embeddings is more effective than keyword search for retrieving documents relevant to user queries. Although keyword search might perform better with simpler queries where the meaning closely aligns with the words used, we can't expect users to tailor their queries to fit the limitations of a search engine. Companies need a search engine to help employees find the documents they need based on their queries. A good engine will work for the employees, not the other way around. Therefore, we recommend (and have built) a customized semantic search engine as the best solution to our clients’ problems.
To learn more about how Synaptiq can help companies harness the power of data and AI, contact us.

Photo by Lysander Yuen on Unsplash
Synaptiq is an AI and data science consultancy based in Portland, Oregon. We collaborate with our clients to develop human-centered products and solutions. We uphold a strong commitment to ethics and innovation.
Contact us if you have a problem to solve, a process to refine, or a question to ask.
You can learn more about our story through our past projects, our blog, or our podcast.