AI-ifying Business Processes
AI applications range from simple rule-based systems to self-learning models, to complex multi-agent systems that...


|
CONSTRUCTION & REAL ESTATE
|
 |
|
Discover how crafting a robust AI data strategy identifies high-value opportunities. Learn how Ryan Companies used AI to enhance efficiency and innovation.
|
| Read the Case Study ⇢ |
|
LEGAL SERVICES
|
 |
|
Discover how a global law firm uses intelligent automation to enhance client services. Learn how AI improves efficiency, document processing, and client satisfaction.
|
| Read the Case Study ⇢ |
|
HEALTHCARE
|
 |
|
A startup in digital health trained a risk model to open up a robust, precise, and scalable processing pipeline so providers could move faster, and patients could move with confidence after spinal surgery.
|
| Read the Case Study ⇢ |
|
LEGAL SERVICES
|
 |
|
Learn how Synaptiq helped a law firm cut down on administrative hours during a document migration project.
|
| Read the Case Study ⇢ |
|
GOVERNMENT/LEGAL SERVICES
|
 |
|
Learn how Synaptiq helped a government law firm build an AI product to streamline client experiences.
|
| Read the Case Study ⇢ |
 |
|
Mushrooms, Goats, and Machine Learning: What do they all have in common? You may never know unless you get started exploring the fundamentals of Machine Learning with Dr. Tim Oates, Synaptiq's Chief Data Scientist. You can read and visualize his new book in Python, tinker with inputs, and practice machine learning techniques for free. |
| Start Chapter 1 Now ⇢ |



A few months ago, I introduced an idea that I was excited to explore surrounding macroinvertebrates, stemming from my passions for fly fishing, aquatic entomology, and water quality. Aquatic insects play vital roles in freshwater ecosystems. They not only serve as food for fish and birds but also act as important indicators of water quality and ecosystem health.
We had some extra cycles earlier this year and ran with the idea as an “internal project” starting with a feasibility study. I’m excited to share what we’ve built and learned since that time. You can download our feasibility study below which details our background, methodology, and findings:
A feasibility study is typically the first technical step we take with any vetted idea. It allows us to determine how much effort or cost is required to significantly improve an existing solution or develop a valuable, new solution.
Our hypothesis was that we could successfully classify three taxonomic orders of aquatic insects (Trichoptera, Ephemeroptera, and Plecoptera) with 90% accuracy using publicly available data collected by citizen scientists.
We embarked on a multi-step process which entailed data harvesting, data preparation, model training, model evaluation, and model refinement. Our journey started with data harvesting, where we tapped into a vast online database created by citizen scientists, called iNaturalist. With over 130 million images (and manually assigned labels) to choose from, we filtered and curated 54,352 images of Trichoptera (Caddisflies), Ephemeroptera (Mayflies), and Plecoptera (Stoneflies) in the United States - both nymphs and adult forms - using iNaturalist's API.
Next, we prepared our data by dividing the images into training, validation, and test sets. We employed advanced computer vision techniques to augment the training dataset, creating a larger and more diverse set of images to challenge the model.
We also created a benchmark set of images where I, our resident aquatic entomologist, personally validated 113 images using SuperAnnotate. to be used to measure each model’s accuracy.
Next, we started model training, by utilizing variations of the pre-trained ResNet18 model and fine-tuning them with our training set. By leveraging the knowledge gained from analyzing millions of images from the ImageNet dataset, our team taught our models to recognize the intricate features that distinguish each aquatic insect order. Finally, we evaluated the performance of our models against our benchmark data set.
We compiled metrics on each of the models’ output. While the model with the best accuracy rate slightly missed the coveted 90% mark, it was still promising, at 86.40% for our benchmark set.
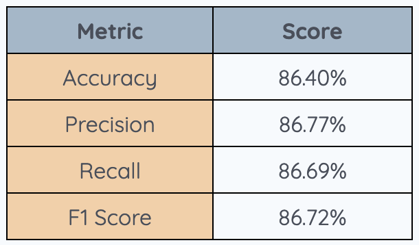
To truly understand the best model's behavior, we turned to a visual aid—the confusion matrix. This matrix allowed us to see the model's predictions and uncover any areas of confusion. It’s like piecing together a puzzle, revealing the subtle patterns and occasional missteps that occurred during the classification process. You can view this graphic in our feasibility study. We also visualized the our model's classification process with a graphic of representative predictions, where "GT" stands for "ground truth" or the true order of the aquatic insects pictured.

If you’re interested in learning more, please read our feasibility study. In the report we stress the importance of scrutinizing the dataset, ensuring accuracy in labeling. We also explore avenues to introduce a balance of true negatives into the training data, providing the model with a more complete understanding of the insects. Exciting possibilities have emerged, such as leveraging additional data sources, refining model architecture, and optimizing hyperparameters. With each step forward, the accuracy rates are bound to improve. And we can’t wait to share more.
Upon completion of the feasibility study we found that our efforts only scratched the surface. As data scientists and outdoor enthusiasts at heart, we are deeply passionate about our ongoing quest to unlock our concept’s full potential. Even further, stemming from our mission to protect the Health of Planet, these sorts of projects are exciting in terms of their potential for impact: soon, anyone with access to a smart device–or who knows someone with one–will be able to protect our environment.
We envision a world where citizen scientists, armed with powerful tools, can actively contribute valuable data to monitor and protect our precious freshwater ecosystems. This vision represents a spirit of collaboration and the anticipation of remarkable discoveries, holding the promise of a brighter future that we are truly excited to bring about. The journey continues, and we cannot wait to continue sharing our findings with you along the way.
By Stephen Sklarew, CEO & co-founder of Synaptiq

Photo by Tomasz on Shutterstock
Synaptiq is an AI and data science consultancy based in Portland, Oregon. We collaborate with our clients to develop human-centered products and solutions. We uphold a strong commitment to ethics and innovation.
Contact us if you have a problem to solve, a process to refine, or a question to ask.
You can learn more about our story through our past projects, blog, or podcast.